C++ Language Basics
by Jetty Nimoy
The magician of the future will use mathematical formulas.
--Aleister Crowley, 1911
Look Alive!
This chapter introduces you to writing small computer programs using the C++ language. Although I assume very little about your previous knowledge, the literacy you gain from this chapter will directly influence your comprehension in subsequent chapters of the book, as most other topics stand on the shoulders of this one. Furthermore, the lessons herein are cumulative, meaning you can't skip one of the topics or you will get lost. If you get stuck on one of the concepts, please seek help in understanding specifically the part that did not make sense before moving on to the next topic. Following the lessons with this sort of rigor ensures that not only will you get the most out of openFrameworks, but computers in general.
Iteration
I did most of my drawing and painting in the mid-nineties, a high school AP art student sporting a long black ponytail of hair shaved with a step, round eyeglasses, and never an article of clothing without spill, fling, smattering, or splotch of Liquitex Basics acrylic paint. Bored out of my mind in economics class, playing with my TI-82 graphing calculator, I discovered something that flipped a light bulb on in my heart. Unlike smaller calculators around my house growing up, the TI-82 had a thick instruction manual. Amidst sections in this manual about trigonometry functions and other dry out-of-reach science, something caught my thirsty, young eye: a sexy black-on-white pyramid with smaller upside-down pyramids infinitely nested inside, shown in Figure 1.

This fractal, the famous Sierpinski triangle, accompanied about twenty-five computer instructions making up the full SIERPINS program. I looked closer at the code, seeing a few numeric operations – nothing too advanced, and most of it was commanding words, like "do this", or "if something then do another thing". I was able to key in the code from the book into the graphing calculator and run the program. At first, just a blank LCD panel. Slowly a few random pixels switched to black here and there, not really showing any pattern. After a few more seconds, the scene filled in and I could already see faint outlines of triangles. After a good long time, my calculator finally matched the picture in the book. My mind was officially blown. Certain things did not make sense. What sort of miracle of nature caused such a complex form to come from so little instruction? The screen had over six thousand pixels in it, so why is it that a mere twenty-five instructions was all it took to create this amazing, organism-like artwork? Whose artwork was it? Might I derive a new work from it? Rarely had I ever seen such a magical reward coming from so little work. I had found my new basics. I felt the need to understand the program because (I decided) it was important. I went back into the code and changed some of the numbers, then ran the program again. The screen went blank, then drew a different picture, only this time, skewed to the left, falling out of the viewport. Feeling more courageous, I attempted to change one of the English instructions, and the machine showed an error, failing to run.

The cycle illustrated in Figure 2 is an infinitely repeating loop that I have had a great pleasure of executing for a couple decades and I still love what I do. Each new cycle never fails to surprise me. As I pursue what it means to create a program, and what it means to create software art. The process of iteratively evolving a list of computer instructions always presents as much logical challenge as it does artistic reward. Very few of those challenges have been impossible to solve, especially with other people available to collaborate and assist, or by splitting my puzzle into smaller puzzles. If you have already written code in another environment like Processing, Javascript, or even HTML with CSS, then this first important lesson might seem too obvious.

For those just now familiarizing themselves with what it means to write small programs, it is important to understand the iterative nature of the code writing process. The anecdote in Figure 3 shows what this process is not. Rarely would you ever enter some code into the editor just once, and expect to hit compile and see your finished outcome. It is natural, and commonly accepted for programs to start small, have plenty of mistakes (bugs), and evolve slowly toward a goal of desired outcome or behavior. In fact it is so commonplace that to make the former assumption is a downright programmer's mistake. Even in older days when programs were hand-written on paper, the author still needed to eyeball the code obsessively in order to work out the mistakes; therefore the process was iterative. In learning the C++ language, I will provide tiny code examples that you will be compiling on your machine. The abnormal part is typing the code from the book into the editor, and (provided your fingers do not slip) the program magically runs. I am deliberately removing the troubleshooting experience in order to isolate the subject matter of the C++ language itself. Later on, we will tackle the commonplace task of debugging (fixing errors) as a topic all its own.
Compiling My First App
Let us start by making the smallest, most immediate C++ program possible, then use the convenient environment to test small snippets of C++ code throughout this chapter. In order to do that, we must have a compiler, which is a program that translates some code into an actual runnable app, sometimes referred to as the executable file. C++ compilers are mostly free of charge to download, and in a lot of cases, open source. The apps we generate will not automatically show up in places like Apple's App store, Google Play, Steam, Ubuntu Apps Directory, or Pi Store. Instead, they are your personal, private program files and you will be responsible for manually sharing them later on. In the following chapter oF Setup and Project Structure, the compiler will sit on your local computer, able to run offline. For now, we will be impatient and compile some casual C++ on the web using a convenient tool by Sphere Research Labs. Please open your web browser and go to ideone (http://ideone.com).
You will notice right away that there is an editor already containing some code, but it may be set to another language. Let's switch the language to C++14 if it is not already in that mode. Down at the bottom left of the editor, press the button just to the left of "stdin", as shown in Figure 4. The label for this button could be any number of things.

A menu drops down with a list of programming languages. Please choose C++14, shown in Figure 5.

Notice that the code in the editor changed, and looks something like figure 6.

This is just an empty code template that does nothing, and creates no errors. The numbers in the left hand gutter indicate the line number of the code. Press the green button labeled Run. You will see a copy of the code, "Success" in the comments, and the section labeled stdin (standard input) will be empty. stdout (standard output) will also be empty.
Interlude on Typography
Most fonts on the web are variable width, meaning the letters are different widths; the eye finds that comfortable to read. Fonts can also be fixed-width, meaning all the letters (even the W and the lowercase i) are the same width. Although this may look funny and quaint like a typewriter, it serves an important purpose. A fixed width font makes a block of text into a kind of game board, like chess squares or graphing paper. Computer programming code is generally presented in fixed-width typesetting, because it is a form of ASCII-art. The indentation, white space characters, and repetitive patterns are all important to preserve and easily eyeball for comparison. Every coder I know except artist Jeremy Rotsztain uses some manner of monospaced font for their code. Some typeface suggestions are Courier, Andale Mono, Monaco, Profont, Monofur, Proggy, Droid Sans Mono, Deja Vu Sans Mono, Consolas, and Inconsolata. From now on, you will see the font style switch to this inline style . . .
and this style encased in a block . . .. . . and that just means you are looking at some code.
Comments
Now please press Edit (Figure 7) at the top left of the code editor.

You will see a slightly different editing configuration but the same template code will still be editable at the top. We will now edit the code. Find line 5, where it says:
// your code goes here .A line beginning with a double forward slash is called a comment. You may type anything you need to in order to annotate your code in a way you understand. Sometimes it's useful to “comment out code” by placing two forward-slashes before it, because that deactivates the C++ code without deleting it. Comments in C++ can also take up multiple lines, or insert like a tag. The syntax for beginning and ending comment-mode is different. Everything between the /* and the */ becomes a comment:
/*
this is a multi-line comment.
still in comment mode.
*/Please delete the code on line 5 and replace it with the following statement:
cout << "Hello World" << endl;This line of code tells the computer to say "Hello World" into an implied text-space known as standard output (aka. stdout). When writing a program, it is safe to expect stdout to exist. The program will be able to "print" text into it. Other times, stdout's just a window pane in your coding environment that's used for troubleshooting.
You may put almost anything between those quotes. The quoted phrase is a called a string of text. More specifically, it is a c-string literal. We will cover more on strings later in this chapter. In the code, the chunk cout << part means "send the following stuff to stdout in a formatted way." The last chunk << endl means "add a carriage return (end-of-line) character to the end of the hello world message." Finally, at the very end of this line of code, you see a semicolon (;).
In C++, semicolons are like a full stop or period at the end of the sentence. We must type a semicolon after each statement, and usually this is at the end of the line of code. If you forget to type that semicolon, the compile fails. Semicolons are useful because they allow multiple statements to share one line, or a single statement to occupy several lines, freeing the programmer to be flexible and expressive with one's whitespace. By adding a semicolon you ensure that the compiler does not get confused: you help it out and show it where the statement ends. When first learning C or C++, forgetting the semicolon can be an extremely common mistake, and yet it is necessary for the code to compile. Please take extra care in making sure your code statements end in semicolons.
While you typed, perhaps you noticed the text became multi-colored all by itself. This convenient feature is called syntax-coloring (or syntax-highlighting) and can subconsciously enhance one's ability to read the code, troubleshoot malformed syntax, and assist in searching. Each tool will have its own syntax coloring system so if you wish to change the colors, please expect that it's not the same thing as a word processor, whose coloring is something you add to the document yourself. A code editor will not let me assign the font "TRON.TTF" with a glowing aqua color to just endl (which means end-of-line). Instead, I can choose a special style for a whole category of syntax, and see all parts of my code styled that way as long as it's that type of code. In this case, both cout and endl are considered keywords and so the tool colors them black. If these things show up as different colors elsewhere, please trust that it's the same code as before, since different code editors provide different syntax coloring. The entire code should now look like this:
#include <iostream>
using namespace std;
int main(){
cout << "Hello World" << endl;
return 0;
}Now press the green ideone it! button at the bottom right corner and watch the output console, which is the bottom half of the code editor, just above that green button. You will see orange status messages saying things like “Waiting for compilation,” “Compilation,” and “Running”. Shortly after, the program will execute in the cloud and the standard output should show up on that web page. You should see the new message in Figure 8.

You made it this far. Now give yourself a pat on the back. You just wrote your first line of C++ code; you analyzed it, compiled it, ran it, and saw the output.
Beyond Hello World
Now that we've gotten our feet wet, let's go back and analyze the other parts of the code. The first line is an include statement:
#include <iostream>Similar to import in Java and CSS, #include is like telling the compiler to cut and paste some other useful code from a file called iostream.h1 at that position in the file, so you can depend on its code in your new code. In this case, iostream.h provides cout and endl as tools I can use in my code, just by typing their names. In C++, a filename ending in .h is called a header file, and it contains code you would include in an actual C++ implementation file, whose filename would end in .cpp. There are many standard headers built into C++ that provide various basic services – in fact too many to mention here. If that wasn't enough, it's also commonplace to add an external library to your project, including its headers. You may also define your own header files as part of the code you write, but the syntax is slightly different:
#include "MyCustomInclude.h"In openFrameworks, double quotes are used to include header files that are not part of the system installation.
What's with the # ?
It's a whole story, but worth understanding conceptually. The include statement is not really C++ code (notice the absence of semicolon). It is part of a completely separate compiler pass called preprocessor. It happens before your actual programmatic instructions are dealt with. They are like instructions for the code compiler, as opposed to instructions for the computer to run after the compile. Using a pound/hash symbol before these preprocessor directives, one can clearly spot them in the file, and for good reason too. They should be seen as a different language, mixed in with the real C++ code. There aren't many C++ preprocessor directives — they are mostly concerned with herding other code. Here are some you might see.
#define #elif #else #endif #error #if #ifdef #include #line #pragma #undef
Let's do an experiment. In the code editor, please comment out the include directive on line 1, then run the code. To comment out the line of code, insert two adjacent forward-slashes at the beginning of the line.
//#include <iostream>The syntax coloring will change to all green, meaning it's now just a comment. Run the code by pressing the big green button at the bottom right, and you'll see something new in the output pane.
prog.cpp: In function 'int main()':
prog.cpp:5:2: error: 'cout' was not declared in this scope
cout << "Hello World" << endl;
^
prog.cpp:5:27: error: 'endl' was not declared in this scope
cout << "Hello World" << endl;
^The compiler found an error and did not run the program. Instead, in an attempt to help you fix it, the compiler is showing you where it got confused. The first part, prog.cpp: tells you the file that contains the error. In this case, ideone.com saved your code into that default file name. Next, it says In function 'int main()': file showing you the specific section of the code that contains the error, in this case, between the {curly brace} of a function called main. (We will talk about functions and curly braces later). On the next line, we see prog.cpp:5:2:. The 5 is how many lines from the top of the file, and 2 is how many characters rightward from the beginning of the line. Next, we see error: 'cout' was not declared in this scope. That is a message describing what it believes is wrong in the code. In this case, it's fairly correct. iostream.h is gone, and therefore no cout is provided to us, and so when we try to send "Hello World", the compile fails. On the next couple of lines, you see the line of code containing the fallacious cout, plus an extra little up-caret character on the line beneath it, and that is supposed to be an arrow pointing at a character in the code. In this case, the arrow should be sitting beneath the 'c' in cout. The system is showing you visually which token is at fault. A second error is shown, and this time, the compiler complains that there is no endl. Of course, we know that in order to fix the error, we need to include <iostream> so let us do that now. Please un-comment line 1 and re-run the code.
#include <iostream>When using openFrameworks, you have choice of tools and platforms. Each one shows you an error in a different way. Sometimes the editor will open up and highlight the code for you, placing an error talk bubble for more info. Other times, the editor will show nothing, but the compile output will show a raw error formatted similarly to the one above. While sometimes useful that we receive several errors from a compile, it can save a lot of grief if you focus on understanding and fixing the very first error that got reported. After fixing the top error, it is likely that all subsequent errors will elegantly disappear, having all been covered by your first fix. By commenting out that single line of code at the top, we caused two errors.
Namespaces at First Glance
Moving on to line 2, we see:
using namespace std;Let's say you join a social website and it asks you to choose a username. My name is Mx. Jetty Nimoy — username might be JNIMOY. I submit the page and it returns an error, telling me that username is already taken, and I have to choose another, since my former father, Joseph Nimoy, registered before I did and he's got JNIMOY. And so I must use my middle initial T, and create a unique username, JTNIMOY. I just created and resolved a namespace conflict. A namespace is a group of unique names — none are identical. It's possible to have identical names, as long as they are a part of two separate namespaces. Namespaces help programmers avoid stepping on each other's toes by overwriting one another's symbols or hogging the good names. Namespaces also provide a neat and tidy organization system to help us find what we're looking for. In openFrameworks, everything starts with of . . . like ofSetBackground and ofGraphics. This is one technique to do namespace separation because it's less likely that any other names created by other programmers would begin with of. The same technique is used by OpenGL. Every name in the OpenGL API (Application Programming Interface) begins with gl like glBlendFunc and glPopMatrix. In C++ however, it is not necessary to have a strictly disciplined character prefix for your names, as the language provides its own namespacing syntax. In line 2, using namespace std; is telling the compiler that this .cpp file is going to use all the names in the std namespace. Spoiler-alert! those two names are cout and endl. Let us now do an experiment and comment out line 2, then run the code. What sort of error do you think the compiler will return?
/* using namespace std; */It's a very similar error as before, where it cannot find cout or endl, but this time, there are suggested alternatives added to the message list.
prog.cpp:5:2: note: suggested alternative:
In file included from prog.cpp:1:0:
/usr/include/c++/4.8/iostream:61:18: note: 'std::cout'
extern ostream cout; /// Linked to standard output
^The compiler says, "Hey, I searched for cout and I did find it in one of the namespaces included in the file. Here it is. std::cout" and in this case, the compiler is correct. It wants us to be more explicit with the way we type cout, so we express its namespace std (standard) on the left side, connected by a double colon (::). it's sort of like calling myself Nimoy::Jetty. Continuing our experiment, edit line 5 so that cout and endl have explicit namespaces added.
std::cout << "Hello World" << std::endl;When you run the code, you will see it compiles just fine, and succeeds in printing "Hello World". Even though the line that says using namespace std; is still commented out. Now imagine you are writing a program to randomly generate lyrics of a song. Obviously, you would be using cout quite a bit. Having to type std:: before all your couts would get really tedious, and one of the reasons a programming language adds these features is to reduce typing. So although line 2 using namespace std; was not necessary, having it in place (along with other using namespace statements) can keep one's C++ code easy to type and read, through implied context.
Say I'm at a Scrabble party in Manhattan, and I am the only JT. People can just call me JT when it's my turn to play. However, if James Taylor (aka JT) joins us after dinner, it gets a bit confusing and we start to call the Jetties by first and last name for clarity. In C++, the same is also true. I would be Nimoy::JT and he would be Taylor::JT. It's alright to have two different cout names, one from the std namespace, and another from the improved namespace, as long as both are expressed with explicit namespaces; std::cout and improved::cout. In fact, the compiler will complain if you don't.
You will see more double-colon syntax (::) when I introduce classes.
Functions
Moving on, let us take a look at line 4:
int main() {This is the first piece of code that has a beginning and an end, such that it "wraps around" another piece of code. But more importantly, a function represents the statements enclosed within it. The closing end of this function is the closing curly brace on line 7:
}In C++, we enclose groups of code statements inside functions, and each function can be seen as a little program inside the greater program, as in the simplified diagram in figure 9.

Each of these functions has a name by which we can call it. To call a function is to execute the code statements contained inside that function. The basic convenience in doing this is less typing, and we will talk about the other advantages later. Like a board game, a program has a starting position. More precisely, the program has an entry-point expected by the compiler to be there. That entry-point is a function called main. The code you write inside the main function is the first code that executes in your program, and therefore it is responsible for calling any other functions in your program. Who calls your main function? The operating system does! Let's break down the syntax of the main function in this demo. Again, for all you Processing coders, this is old news.
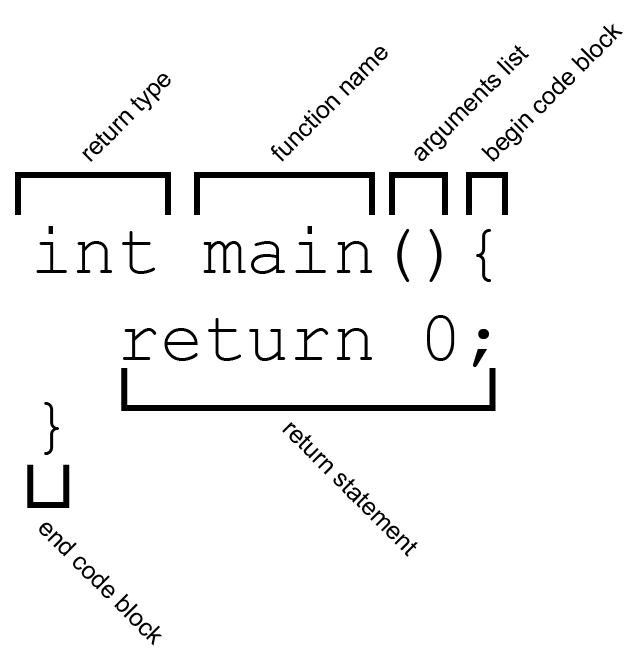
When defining a function, the first token is the advertised return type. Functions can optionally return a value, like an answer to a question, a solution to a problem, the result of a task, or the product of a process. In this case, main promises to return an int, or integer type, which is a whole number with no fraction or decimal component. Next token is the name of our function. The system expects the word "main" in all lower-case, but you will later define your own functions and we will get into naming. Next is an opening and closing parenthesis. Yes, it seems kind of strange to have it there, since there is nothing inside it. Later, we will see what goes in there — but never leave out the pair of parentheses with functions because in a certain way, that is the major hint to the human that it's a function. In fact, from now on, when I refer to a function by name. I'll suffix it with a ( ), for example main() when the function requires no parameter and I'll suffix it with a (...), for example main(...), when the function requires one or more parameters
Next, we see an opening curly bracket. Sometimes this opening curly bracket is on the same line as the preceding closing parenthesis, and other times, you will see it on its own new line. It depends on the personal style of the coder, project, or group — and both are fine. For a complete reference on different indent styles, see the Wikipedia article on Indent Style (http://en.wikipedia.org/wiki/Indent_style).
In between this opening curly bracket and the closing one, we place our code statements that actually tell the computer to go do something. In this example, I only have one statement, and that is the required return. If you leave this out for a function whose return type is int, then the compiler will complain that you broke your promise to return an int. In this case, the operating system interprets a 0 as "nothing went wrong". Just for fun, see what happens when you change the 0 to a 1, and run the code.
Custom Functions
We will now define our own function and make use of it as a word template. Type the sample code into your editor and run it.
#include <iostream>
using namespace std;
void greet(string person){
cout << "Hi there " << person << "." << endl;
}
int main() {
greet("moon");
greet("red balloon");
greet("comb");
greet("brush");
greet("bowl full of mush");
return 0;
}The output shows a familiar bedtime story.
Hi there moon.
Hi there red balloon.
Hi there comb.
Hi there brush.
Hi there bowl full of mush.In this new code, notice the second function greet(...) which looks the same but different from main(). It has the same curly brackets to hold the code block, but the return type is different. It has the same pair of parentheses, but this time there is something inside. And what about that required return statement? The void keyword is used in place of a return type when a function does not return anything. So, since greet(...) has a void return type, the compiler will not complain should you leave out the return. In the parentheses, you see string person. This is a parameter, an input-value for the function to use. In this case, it's a bit like find-and-replace. Down in main(), you see I call greet(...) five times, and each time, I put a different string in quotes between the parentheses. Those are arguments.
As an aside, to help in the technicality of discerning between when to call them arguments and when to call them parameters, see this code example:
void myFunction(int parameter1, int parameter2){
//todo: code
}
int main(){
int argument1 = 4;
int argument2 = 5;
myFunction(argument1,argument2);
return 0;
}Getting back to the previous example, those five lines of code are all function calls. They are telling greet(...) to execute, and passing it the one string argument so it can do its job. That one string argument is made available to greet(...)'s inner code via the parameter called person. To see the order of how things happen, take a look at Figure 11.

The colorful line in Figure 11 is the path drawn by an imaginary playback head that steps over the code as it executes. We start at the blue part and go in through the main entry-point, then encounter greet(...), which is where a jump happens. As the line turns green, it escapes out of main() temporarily so it can go follow along greet(...) for a while. About where the line turns yellow, you see it finished executing the containing code inside greet(...) and does a second jump (the return) this time going back to the previous saved place, where it continues to the next statement. The most obvious advantage we can see in this example is the reduction of complexity from that long cout statement to a simple call to greet(...). If we must call greet(...) five times, having the routine encapsulated into a function gives it convenience power. Let's say you wanted to change the greeting from "Good night" to "Show's over ". Rather than updating all the lines of code you cut-and-pasted, you could just edit the one function, and all the uses of the function would change their behavior along with it, in a synchronized way. Furthermore, code can grow to be pretty complex. It helps to break it down into small routines, and use those routines as your own custom building blocks when thinking about how to build the greater software. By using functions, you are liberated from the need to meticulously represent every detail of your system; therefore a function is one kind of abstraction just like abstraction in art. This sort of abstraction is called encapsulation of complexity because it's like taking the big complex thing and putting it inside a nice little capsule, making that big complex thing seem smaller and simpler. It's a very powerful idea — not just in code.
Encapsulation of Complexity
Imagine actor Laurence Fishburne wearing tinted pince-nez glasses, offering you two options that are pretty complicated to explain. On the one hand, he is willing to help you escape from the evil Matrix so that you may fulfill your destiny as the hacker hero, but it involves living life on life's terms and that is potentially painful but whatever. The story must go on and by the way, there is a pretty girl. On the other hand, he is also willing to let you forget this all happened, and mysteriously plant you back in your tiny apartment where you can go on living a lie, none the wiser. These two options are explained in the movie The Matrix and then the main character is offered the choice in the form of colored pills, as a way to simplify an otherwise wordy film scenario. The two complex choices are encapsulated into a simple analogy that is much easier for movie audiences to swallow. See Figure 12.

Rather than repeating back the entire complicated situation, Neo (the main character) needed only to swallow one of the pills. Even if it were real medicine, the idea of encapsulating complexity still applies. Most of us do not have the expertise to practice medicine in the most effective way, and so we trust physicians and pharmacologists to create just the right blend of just the right herbs and chemicals. When you swallow a pill, it is like calling that function because you have the advantage of not needing to understand the depths of the pill. You simply trust that the pill will cause an outcome. The same is true with code. Most of the time, a function was written by someone else, and if that person is a good developer, you are free to remain blissfully ignorant of their function's inner workings as long as you grasp how to properly call their function. In this way, you are the higher-level coder, meaning that you simply call the function but you did not write it. Someone who creates a project in openFrameworks is sitting on the shoulders of the openFrameworks layer. openFrameworks sits on the shoulders of the OpenGL Utility Toolkit, which sits on OpenGL itself, and so on. In other words, an openFrameworks project is a higher-level application of C++, a language with a reputation for lower-level programming. As illustrated in Figure 13, I sometimes run into a problem when I tell people I wrote an interactive piece in C++.

There are a few advantages to using C++ over the other options (mostly scripting) for your new media project. The discussion can get quite religious (read: heated) among those who know the details. If you seek to learn C++, then usually it is because you seek faster runtime performance, because C++ has more libraries that you can snap into your project, or because your mentor is working in that language. An oF project is considered higher-level because it is working with a greater encapsulation of complexity, and that is something to be proud of.
Variables (part 1)
A “thing” is a “think”, a unit of thought
-- Alan Watts
Please enter the following program into ideone and run it.
#include <iostream>
using namespace std;
int main(){
cout << "My friend is " << 42 << " years old." << endl;
cout << "The answer to the life the universe and everything is " << 42 << "." << endl;
cout << "That number plus 1 is " << (42+1) << "." << endl;
return 0;
}The output looks like this:
My friend is 42 years old.
The answer to the life the universe and everything is 42.
That number plus 1 is 43.We understand from a previous lesson that stuff you put between the << operators will get formatted into the cout object, and magically end up in the output console. Notice in the last line, I put a bit of light arithmetic (42+1) between parentheses, and it evaluated to 43. That is called an expression, in the mathematics sense. These three lines of code all say something about the number 42, and so they all contain a literal integer. A literal value is the contents typed directly into the code; some would say "hard wired" because the value is fixed once it is compiled in with the rest.
If I want to change that number, I can do what I know from word processing, and "find-and-replace" the 42 to a new value. Now what if I had 100,000 particles in a 3D world. Some have 42s that need changing, but other 42s that should not be changed? Things can get both heavy and complex when you write code. The most obvious application of variables is that they are a very powerful find-and-replace mechanism, but you'll see that variables are useful for more than that. So let's declare an integer at the top of the code and use it in place of the literal 42s.
#include <iostream>
using namespace std;
int main(){
int answer = 42;
cout << "My friend is " << answer << " years old." << endl;
cout << "The answer to the life the universe and everything is " << answer << "." << endl;
cout << "That number plus 1 is " << (answer+1) << "." << endl;
return 0;
}Now that I am using the variable answer, I only need to change that one number in my code, and it will show up in all three sentences as 42. That can be more elegant than find-and-replace. Figure 18 shows the syntax explanation for declaring and initializing a variable on the same line.

It is also possible to declare a variable and initialize it on two separate lines. That would look like:
int answer;
answer = 42;In this case, there is a moment after you declare that variable when its answer may be unpredictable and glitchy because in C (unlike Java), fresh variables are not set to zero for free — you need to do it. If you don't, the variable can come up with unpredictable values — computer memory-garbage from the past. So, unless you intend to make glitch art, please always initialize your variable to some number upon declaring it, even if that number is zero.
Naming your variable
Notice the arrow below saying "must be a valid name". We invent new names to give our namespaces, functions, variables, and other constructs we define in code (classes, structs, enums, and other things I haven't taught you). The rules for defining a new identifier in code are strict in a similar way that choosing a password on a website might be.
- Your identifier must contain only letters, numbers, and underscores.
- it cannot begin with a number, but it can certainly begin with an underscore.
- The name cannot be the same as one of the language keywords (for example, the word
void)
The following identifiers are okay.
a
A
counter1
_x_axis
perlin_noise_frequency
_ // a single underscore is fine
___ // several underscores are fineNotice lowercase a is a different identifier than uppercase A. Identifiers in C++ are case-sensitive. The following identifiers are not okay.
1infiniteloop // should not start with a number
transient-mark-mode // dashes should be underscores
@jtnimoy // should not contain an @
the locH of sprite 1 // should not contain spaces
void // should not be a reserved word
int // should not be a reserved wordnaming your variable void_int, although confusing, would not cause any compiler errors because the underscore joins the two keywords into a new identifier. Occasionally, you will find yourself running into unqualified id errors. Here is a list of C++ reserved keywords to avoid when naming variables. C++ needs them so that it can provide a complete programming language.
alignas alignof and and_eq asm auto bitand bitor bool break case catch
char char16_t char32_t class compl const constexpr const_cast continue
decltype default delete do double dynamic_cast else enum explicit
export extern false final float for friend goto if inline int long
mutable namespace new noexcept not not_eq nullptr operator or or_eq
override private protected public register reinterpret_cast return
short signed sizeof static static_assert static_cast struct switch
template this thread_local throw true try typedef typeid typename
union unsigned using virtual void volatile wchar_t while xor xor_eqNaming conventions
Differences of habit and language are nothing at all if our aims are identical and our hearts are open.
--Albus Dumbledore
Identifiers (variables included) are written with different styles to indicate their various properties, such as type of construct (variable, function, or class?), data type (integer or string?), scope (global or local?), level of privacy, etc. You may see some identifiers capitalized at the beginning and using CamelCase, while others remain all lower_case_using_underscores_to_separate_the_words. Global constants are found to be named with ALL_CAPS_AND_UNDERSCORES. Another way of doing lower-case naming is to start with a lowercase letterThenCamelCaseFromThere. You may also see a hybrid, like ClassName__functionName__variable_name. These different styles can indicate different categories of identifiers.
More obsessively, programmers may sometimes use what is affectionately nicknamed Hungarian Notation, adding character badges to an identifier to say things about it but also reduce the legibility, for example dwLightYears and szLastName. Naming conventions are not set in stone, and certainly not enforced by the compiler. Collaborators generally need to agree on these subtle naming conventions so that they don't confuse one another, and it takes discipline on everyone's part to remain consistent with whatever convention was decided. The subject of naming convention in code is still a comically heated debate among developers, just like deciding which line to put the curly brace, and whether to use tabs to indent. Like a lot of things in programming, someone will always tell you you're doing it wrong. That doesn't necessarily mean you are doing it wrong.
Variables change
We call them variables because their values vary during runtime. They are most useful as a bucket where we put something (let's say water) for safe keeping. As that usually goes, we end up going back to the bucket and using some of the water, or mixing a chemical into the water, or topping up the bucket with more water, etc. A variable is like an empty bucket where you can put your stuff. Figure 19 shows a bucket from the game Minecraft.

If a computer program is like a little brain, then a variable is like a basic unit of remembrance. Jotting down a small note in my sketchbook is like storing a value into a variable for later use. Let's see an example of a variable changing its value.
#include <iostream>
using namespace std;
int main(){
int counter = 0;
cout << counter;
counter = 1;
cout << counter;
counter = 2;
cout << counter;
counter = 3;
cout << counter;
counter = 4;
cout << counter;
counter = 5;
cout << counter;
return 0;
}The output should be 012345. Notice the use of the equal sign. It is different than what we are accustomed to from arithmetic. In the traditional context, a single equal sign means the expressions on both sides would evaluate to the same value. In C, that is actually a double equal (==) and we will talk about it later. A single equal sign means "Solve the expression on the right side and store the answer into the variable named on the left side". It takes some getting used to if you haven't programmed before. If I were a beginning coder (as my inner child is perpetually), I would perhaps enjoy some alternative syntax to command the computer to store a value into a variable. Something along the lines of: 3 => counter as found in the language ChucK by Princeton sound lab, or perhaps something a bit more visual, as my repurposing of the Minecraft crafting table in figure 20.

The usefulness of having the variable name on the left side rather than the right becomes apparent in practice since the expressions can get quite lengthy! Beginning a line with varname = ends up being easier for the eyeball to scan because it's guaranteed to be two symbols long before starting in on whatever madness you plan on typing after the equals sign.
Analyzing the previous code example, we see the number increments by 1 each time before it is output. I am repeatedly storing literal integers into the variable. Since a programming language knows basic arithmetic, let us now try the following modification:
#include <iostream>
using namespace std;
int main(){
int counter = 0;
cout << counter;
counter = counter + 1;
cout << counter;
counter = counter + 1;
cout << counter;
counter = counter + 1;
cout << counter;
counter = counter + 1;
cout << counter;
counter = counter + 1;
cout << counter;
return 0;
}The output should still be 012345. By saying counter = counter + 1, I am incrementing counter by 1. More specifically, I am using counter in the right-hand "addition" expression, and the result of that (one moment later) gets stored into counter. This seems a bit funny because it talks about counter during two different times. It reminds me of the movie series, Back to the Future, in which Marty McFly runs into past and future versions of himself. See Figure 21.

Great Scott, that could make someone dizzy! But after doing it a few times, you'll see it doesn't get much more complicated than what you see there. This is a highly practical use of science fiction, and you probably aren't attempting to challenge the fabric of spacetime (unless you are Kyle McDonald, or maybe a Haskell coder). The point here is to modify the contents of computer memory, so we have counter from one instruction ago, in the same way that there might already be water in our bucket when we go to add water to it. Figure 22 shows bucket = bucket + water.

Incrementing by one, or adding some value to a variable is in fact so commonplace in all programming that there is even syntactic sugar for it. Syntactic Sugar is a redundant grammar added to a programming language for reasons of convenience. It helps reduce typing, can increase comprehension or expressiveness, and (like sugar) makes the programmer happier. The following statements all add 1 to counter.
counter = counter + 1; // original form
counter += 1; // "increment self by" useful because it's less typing.
counter++; // "add 1 to self" useful because you don't need to type a 1.
++counter; // same as above, but with a subtle difference.Let's test this in the program.
#include <iostream>
using namespace std;
int main(){
int counter = 0;
cout << counter;
counter++;
cout << counter;
counter++;
cout << counter;
counter++;
cout << counter;
counter++;
cout << counter;
counter++;
cout << counter;
return 0;
}Yes, it's a lot less typing, and there are many ways to make it more concise. Here is one way.
#include <iostream>
using namespace std;
int main(){
int counter = 0;
cout << counter++;
cout << counter++;
cout << counter++;
cout << counter++;
cout << counter++;
cout << counter++;
return 0;
}The answer is still 012345. The postfix incrementing operator will increment the variable even while it sits inside an expression. Now let's try the prefix version.
#include <iostream>
using namespace std;
int main(){
int counter = 0;
cout << ++counter;
cout << ++counter;
cout << ++counter;
cout << ++counter;
cout << ++counter;
cout << ++counter;
return 0;
}If you got the answer 123456, that is no mistake! The prefix incrementing operator is different from its postfix sister in this very way. With counter initialized as 0, ++counter would evaluate to 1, while counter++ would still evaluate to 0 (but an incremented version of counter would be left over for later use). The output for the following example is 1112.
#include <iostream>
using namespace std;
int main(){
int counter = 0;
cout << ++counter; // 1: increments before evaluating
cout << counter; // 1: has NOT changed.
cout << counter++; // 1: increments after evaluating
cout << counter; // 2: evidence of change.
return 0;
}For arithmetic completeness, I should mention that the subtractive decrementing operator (counter--) also exists. Also, as you might have guessed by now, if one can say counter + 1, then a C compiler would also recognize the other classic arithmetic like counter - 3 (subtraction), counter * 2 (asterisk is multiplication), counter / 2 (division), and overriding the order of operations by using parentheses, such as (counter + 1) / 2 evaluating to a different result than counter + 1 / 2. Putting a negative sign before a variable will also do the right thing and negate it, as if it were being subtracted from zero. C extends this basic palette of maths operators with boolean logic and bitwise manipulation; I will introduce them in Variables part 2.
There are a few more essentials to learn about variables, but we're going to take what we've learned so far and run with it in the name of fun. In the meantime, give yourself another pat on the back for making it this far! You learned what variables are, and how to perform basic arithmetic on them. You also learned what the ++ operator does when placed before and after a variable name.
The C++ language gets its name from being the C language plus one.
Conclusion
Congratulations on getting through the first few pages of this introduction to C++. With these basic concepts, you should be able to explore plenty far on your own, but I will admit that it is not enough to prepare you to comprehend the code examples in the rest of ofBook. Because of limited paper resources, what you've seen here is a "teaser" chapter for a necessarily lengthier introduction to the C++ language. That version of this chapter got so big that it is now its own book — available unabridged on the web, and possibly in the future as its own companion book alongside ofBook. Teaching the C++ language to non-programmers is indeed a large subject all itself, which could not be effectively condensed to 35 pages, let alone the 100+ page book it grew to be. If you're serious about getting into openFrameworks, I highly recommend you stop and read the unabridged version of this chapter before continuing in ofBook, so that you may understand what you are reading. You will find those materials here
PS.
Stopping the chapter here is by no means intended to separate what is important to learn about C++ from what is not important. We have simply run out of paper. In lieu of how important the rest of this intro to C++ is, and based on ofZach's teaching experience, here is more of what you'll find in the unabridged version:
Variables exist for different periods of time - some for a long time, and some for a small blip in your program's lifecycle. This subject of scope is covered in the unabridged version of this book, entitled Variables (part 2).
Variables have a data type. For example, one holds a number while another holds some text. More about that in Fundamental Types.
It's important to reiterate that unlike Processing, variables do not necessarily start with a zero value. You must initialize them with your desired value, and otherwise there's no telling what will be waiting there for you. You'll find additional discussion of this phenomenon in the introduction to arrays.
The best way to predict your future is to create it.
--Abraham Lincoln
Note: when including standard headers using < > brackets, the .h is implicit, i.e. the modern standard is to drop the .h extension from the include statement. When including external libraries with double quotes, however, the .h extension must be written explicitly.↩